In the era of big data and advanced artificial intelligence, the performance of deep learning models often hinges on the quality of the datasets used to train them. Unfortunately, large datasets typically come with inherent imperfections, particularly label noise—incorrect or misleading labels that can detrimentally affect model performance during evaluation. When deep learning algorithms try to classify or predict using these flawed datasets, the results can be less than optimal, showcasing the necessity for innovative solutions that address this critical issue.
A team of researchers from Yildiz Technical University—Enes Dedeoglu, H. Toprak Kesgin, and Prof. Dr. M. Fatih Amasyali—has taken significant steps towards mitigating the impact of label noise on model accuracy by proposing a new method called Adaptive-k. As detailed in their publication in the *Frontiers of Computer Science*, this approach adeptly navigates the optimization landscape amidst the challenges posed by label inaccuracies, thus enabling more efficient training of deep learning models.
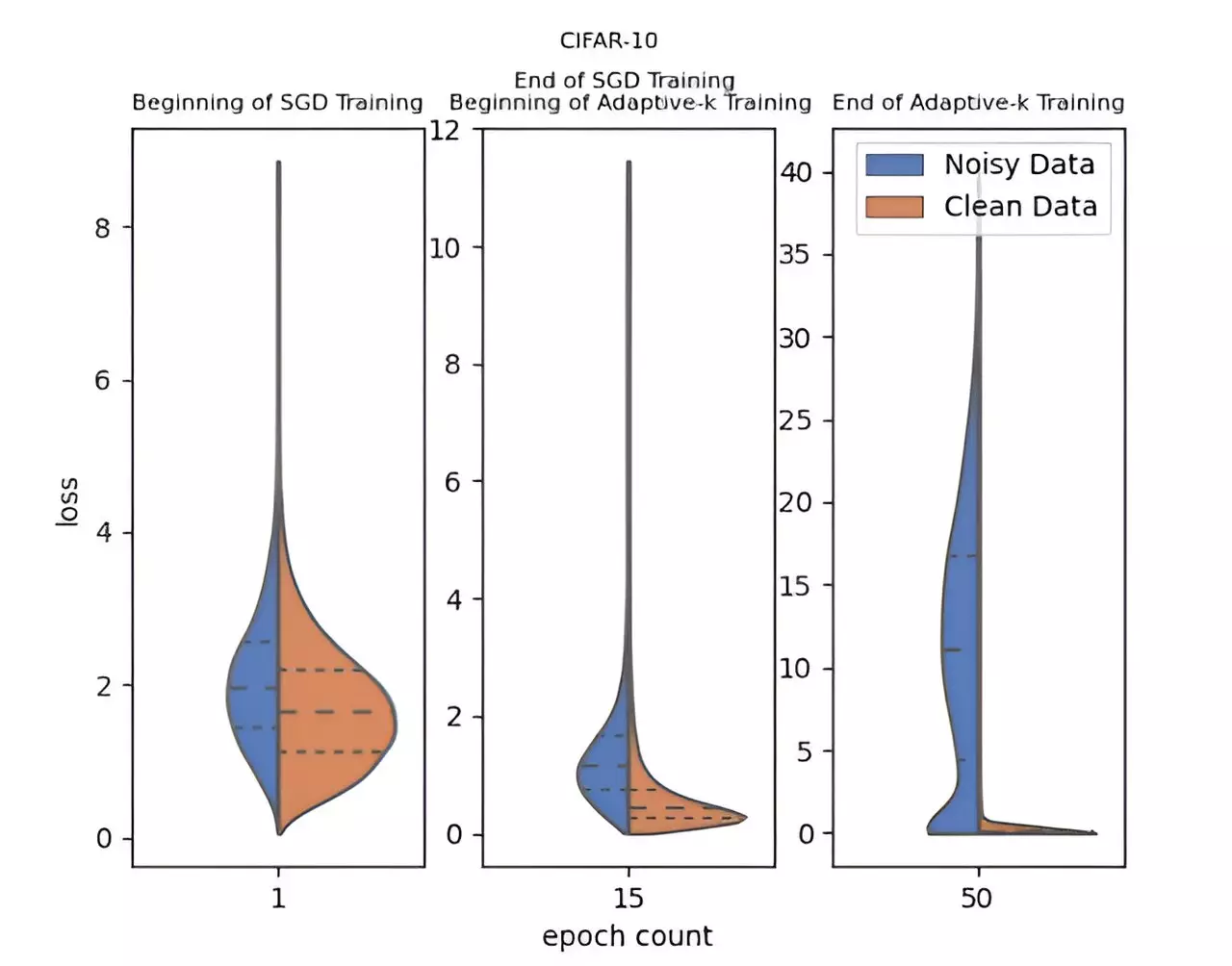
What sets the Adaptive-k method apart from traditional strategies is its dynamic approach to selecting the mini-batch samples used for updates. By adaptively determining how many samples to include, Adaptive-k not only improves the filtering of noisy labels but also fosters a more robust learning environment. This capability allows for better handling of noisy datasets, making it a promising tool for data scientists looking to improve model reliability without necessitating extensive adjustments or additional training.
Adaptive-k shows remarkable promise, achieving performance levels that approach the ideal Oracle scenario—where noisy samples are entirely excluded. Comparative studies have demonstrated that Adaptive-k outperforms other notable algorithms, including Vanilla, MKL, Vanilla-MKL, and Trimloss, across both image and text datasets. This empirical validation underscores the method’s effectiveness, providing tangible benefits for practitioners grappling with noisy data.
Moreover, the versatility of Adaptive-k is highlighted by its compatibility with various optimization algorithms such as Stochastic Gradient Descent (SGD), Stochastic Gradient Descent with Momentum (SGDM), and Adam. This adaptability not only enhances the applicability of the method across different frameworks but also paves the way for its integration into existing deep learning workflows with minimal friction.
The implications of the Adaptive-k method extend far beyond its initial implementation; the research team plans to refine the algorithm further, explore additional applications, and enhance its performance metrics. This focus on continual improvement reflects the evolving nature of deep learning and the ongoing quest for greater accuracy and efficiency in training protocols.
The introduction of Adaptive-k represents a significant milestone in addressing the persistent problem of label noise in deep learning datasets. By offering a straightforward, effective, and adaptable solution, this innovative algorithm has the potential to elevate the field of machine learning, leading to more reliable models that can thrive in the face of data imperfections. As future research unfolds, Adaptive-k may well become a cornerstone technique in the quest for high-performance deep learning applications.
Leave a Reply