The emergence of speech emotion recognition (SER) represents a groundbreaking intersection of artificial intelligence and human communication. Utilizing sophisticated deep learning algorithms, these systems aim to decode human emotional states through vocal cues like tone, pitch, and rhythm. With applications ranging from mental health diagnostics to customer service enhancements, the significance of SER cannot be overstated. However, recent investigations point to alarming weaknesses within these models that could undermine their reliability, particularly in the face of adversarial attacks.
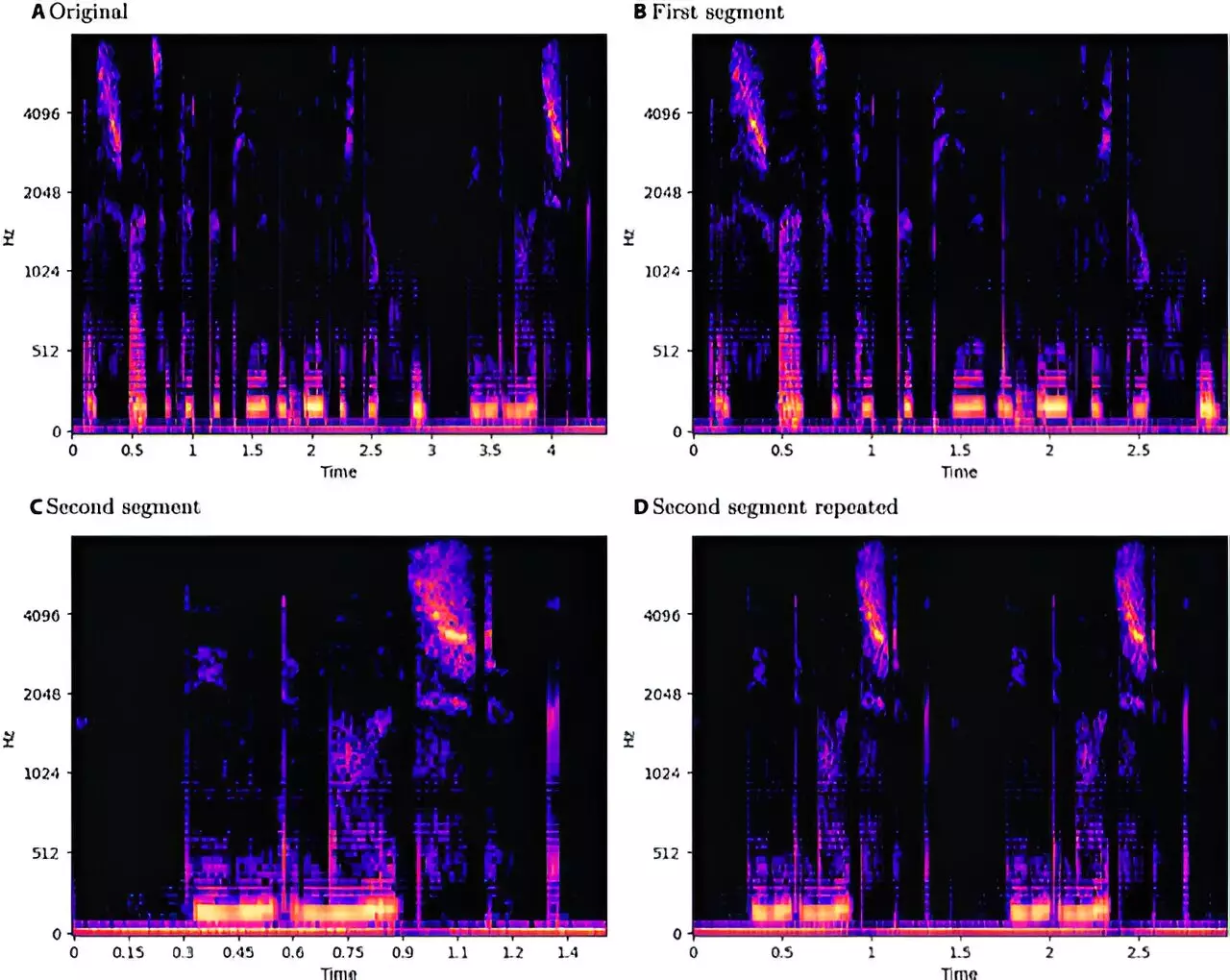
Deep learning models, while powerful, are inherently fragile. Adversarial attacks are strategic manipulations of input data designed to mislead these models into generating incorrect outputs. A study from the University of Milan, published in Intelligent Computing, sheds light on the susceptibility of SER models, particularly convolutional neural network long short-term memory (CNN-LSTM) architectures, to such attacks. The research reveals that both white-box attacks, where the attacker has full knowledge of the model, and black-box attacks, where they do not, significantly impair the performance of SER systems. This vulnerability raises profound concerns, as distorted emotional input could lead to misinterpretations that exacerbate existing issues, particularly in applications requiring high emotional accuracy.
The researchers employed a comprehensive methodology, exploring attacks on multiple datasets across various languages. With the inclusion of the EmoDB, EMOVO, and RAVDESS databases, they sought to investigate the intricacies of emotional expression in German, Italian, and English. The study incorporated a diverse range of adversarial techniques, including advanced methods like the Fast Gradient Sign Method and the Jacobian-based Saliency Map Attack. Strikingly, even the black-box strategies, particularly the Boundary Attack, yielded unexpectedly effective results, occasionally outpacing white-box methods. This finding reveals a stark paradox; attackers can achieve significant distortions without any access to the internal mechanisms of SER models. Such insights highlight a pressing need for improved defenses against manipulation despite the apparent transparency that new methodologies offer.
A particularly intriguing aspect of the study is its examination of how gender and linguistic differences influence model vulnerabilities. The analysis revealed that while there were only slight variations in performance across different languages, English was notably more susceptible to adversarial attacks than Italian. Furthermore, the data indicated that male samples exhibited marginally superior robustness against both white-box and black-box attacks compared to female samples, although these discrepancies were minimal. This nuanced understanding of how gender and language impact vulnerability offers valuable insights for tailoring future SER systems to better withstand adversarial assaults.
While the revelations of potential weaknesses within SER models might induce concern, the authors argue for the necessity of transparency in research. By openly sharing vulnerabilities, researchers can create a more informed community that is better equipped to combat adversarial challenges. This approach serves a dual purpose: it not only aids defenders in reinforcing their systems but also provides attackers with the knowledge required to improve their techniques. The ethical implications of this transparency are profound—rather than hindering progress, revealing model vulnerabilities can lead to robust advancements in SER technology, contributing to safer applications in real-world contexts.
While recent research underscores the vulnerabilities of speech emotion recognition technologies, it also highlights a pathway toward enhancing their resilience. The combination of a deeper understanding of adversarial strategies and a commitment to transparency can pave the way for more secure SER frameworks. Researchers and practitioners must work collaboratively to innovate defenses that can withstand evolving threats. As the field of speech emotion recognition continues to grow, fostering a culture of open dialogue about both strengths and weaknesses will be crucial in shaping the future of this transformative technology.
Leave a Reply