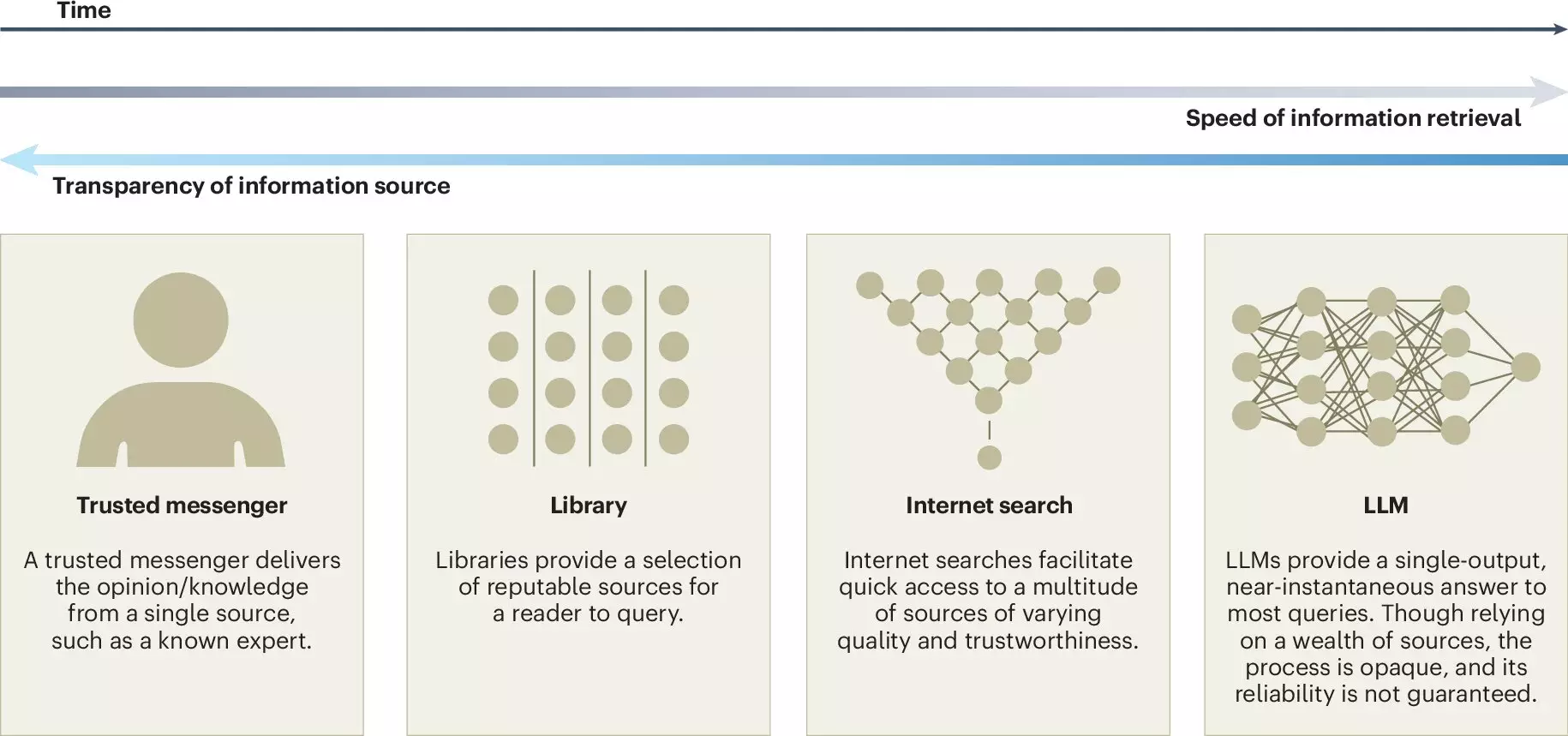
In recent years, the rise of large language models (LLMs) like ChatGPT has ushered in a transformative period in communication and information processing. These advanced artificial intelligence systems use vast datasets and sophisticated algorithms to generate human-like text, thus influencing various aspects of daily life. A noteworthy article published in *Nature Human Behaviour* offers a detailed exploration of both the advantages and challenges associated with LLMs, particularly in relation to collective intelligence. This article draws insights from an interdisciplinary team comprising researchers from the Copenhagen Business School and the Max Planck Institute for Human Development, highlighting key concerns and recommendations for maximizing the positive impact of LLMs.
Collective intelligence—a term that represents the aggregated knowledge and skills of a group—has long been a fundamental aspect of human interaction. Whether in small teams collaborating on projects or large communities contributing to platforms like Wikipedia, this collective potential often leads to outcomes that far surpass what individuals alone can achieve. The article emphasizes the capacity of LLMs to bolster this form of intelligence by facilitating communication, idea generation, and decision-making across diverse groups. By integrating and synthesizing information, these models can enhance discussions and problem-solving, allowing for a more inclusive participation from various demographic backgrounds.
One significant advantage of LLMs is their ability to democratize information access. They serve as powerful tools to break linguistic barriers, offering translation services that enable individuals from different backgrounds to engage equally in conversations. Additionally, LLMs can streamline the process of idea generation by curating relevant information, summarizing opinions, and aiding in reaching consensus, thereby enriching collective discourse. As Ralph Hertwig, one of the study’s co-authors, suggests, this capability is essential in an era where information overload can overwhelm individual understanding and decision-making skills.
Furthermore, the integration of LLMs into collective decision-making processes can help maintain the flow of ideas, allowing groups to quickly iteratively improve upon suggestions. Thus, LLMs can be seen as enablers—tools designed to augment human creativity and collaborative efforts.
Despite their potential benefits, the deployment of LLMs in collective intelligence scenarios also raises significant ethical and social concerns. For instance, the reliance on these AI models could inadvertently diminish public engagement in knowledge-sharing platforms. As noted by Jason Burton, one of the lead researchers, an overdependence on proprietary models may threaten the diversity and inclusiveness of the digital knowledge landscape. This transition could lead people to accept generated content passively, resulting in diminished contributions to platforms that rely on collective input, such as Wikipedia and Stack Overflow.
Another pressing issue is the potential for bias within LLM-generated responses. Since these models learn from pre-existing information available online, they may inadvertently propagate dominant narratives while sidelining minority viewpoints. This phenomenon can facilitate a false consensus effect, leading to a misrepresentation of public opinions and creating an environment where pluralistic ignorance prevails. In essence, while LLMs can aggregate information, they risk homogenizing knowledge and stifling the rich diversity of perspectives that should inform collective decision-making.
The article advocates for a proactive approach to harnessing the power of LLMs while mitigating their risks. The authors recommend greater transparency regarding the design and training of these models, including clear disclosures of the sources of training data. External audits and monitoring mechanisms could significantly contribute to understanding how these models operate and the implications of their deployment. By ensuring accountability in LLM development, researchers and developers can address critical concerns relating to bias and representation.
Moreover, the article includes informative sections that explore the intersection of LLMs and collective intelligence. These snippets not only shed light on how LLMs can be trained to simulate human group dynamics but also identify open research questions that must be tackled. Among those inquiries are how to prevent knowledge uniformity and how to assign credit and accountability when LLMs are involved in collaborative processes.
The discourse surrounding large language models encapsulates a tension—between their transformative potential in enhancing collective intelligence and the myriad risks they pose to information diversity and representation. As we navigate this complex landscape, a balanced approach is crucial. By fostering transparency, encouraging diverse contributions, and scrutinizing the content generated by LLMs, society can leverage the advantages of these models while safeguarding the richness of human knowledge. The insights provided by contemporary research underline the importance of deliberate and informed integration of LLMs into our collective intelligence efforts, shaping a future that embraces both innovation and ethical responsibility.
Leave a Reply